
روش نرمال سازی Z-Score
نرمالسازی داده ها
نرمال سازی یکی از تکنیک های مقیاس بندی ( Scaling )، نگاشت ( mapping ) در مرحله پیش پردازش ( preprocessing stage) در فرآیند داده کاوی است. در این روش میتوانیم داده ها را از بازه فعلی آن به یک بازه دیگر نگاشت کنیم. این رویکرد میتواند کمک زیادی در اهداف پیش بینی و تجزیه و تحلیل های ما داشته باشد، بنابراین با توجه به تنوع مدل های پیش بینی در داده کاوی و به منظور حفظ این تنوع، تکنیک های نرمالسازی به ما کمک میکند تا این پیش بینی ها را به یکدیگر نزدیک کنیم. از جمله این تکنیک های نرمال سازی میتوان به تکنیک Min-Max normalization، Z-score و Decimal scaling اشاره کرد که در این مقاله به طور مختصر به نحوه کارکرد Z-score میپردازیم.
روش نرمال سازی Z-Score
مقدار Z-score از طریق رابطه زیر محاسبه میشود که در آن، μ مقدار میانگین جمعیت آماری و σ انحراف معیار جمعیت میباشد. مقدار قدر مطلق ( absolute value) محاسبه شده برای z، فاصله آن ردیف از داده ها را از میانگین کل جمعیت بر حسب انحراف معیار نشان میدهد. هنگامی که این مقدار مثبت باشد، یعنی Z-score بالاتر از میانگین و اگر منفی باشد، نشان دهنده کمتر بود آن مقدار خاص، از میانگین کل داده ها میباشد.
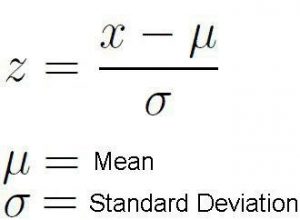
نکته قابل توجه اینکه، محاسبه Z نیازمند آن است که ما به میانگین و انحراف معیار کل جامعه دسترسی داشته باشیم و امکان بکارگیری این پارامترها بر اساس نمونه محدودی از کل جمعیت وجود ندارد. اما اگر نمونه قابل توجهی از داده ای جامعه به عنوان نمونه در دسترس باشد در اساس قضیه حد مرکزی در علم آمار و احتمالات میتوان نتیجه گرفت که میانگین نمونه به میانگین جامعه میل میکند. لذا میتوان با در دست داشتن داده های جمعآوری شده مقادیر میانگین و انحراف از معیار را به صورت زیر برآورد کرد:
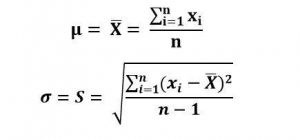
کاربرد Z-Score در تشخیص داده های پرت
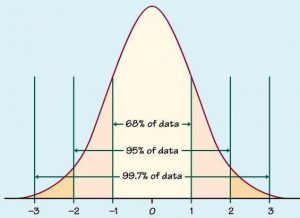
براساس ویژگی های توزیع نرمال مطابق شکل زیر، 99.7% داده ها در فاصلهی 6 انحراف معیار از میانگین قرار، دارند. لذا میتوان نتیجه گرفت که 0.3% داده ها که خارج از این حدود قرار میگیرند، رفتاری نامتعارف نسبت به اکثریت داده ها دارند.
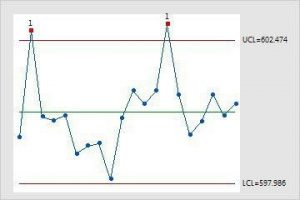
با استفاده از خاصیت فوق از روش Z-score، برای کنترل کیفیت محصولات تولیدی در کارخانه ها استفاده میشود. بدین منظور به محاسبه Z-score برای یک محصول خاص پرداخته و با توجه به استاندارد های سازمان و بکارگیری حدود مشخصات یا همان specification limits ها سعی میکند تا از تولید محصولات معیوب و به دور از استاندارد های سازمان، جلوگیری کند. به عنوان مثال اگر نمودار زیر، بیانگر ارتفاع پایه های یک میز اداری باشد، مواردی که با رنگ قرمز مشخص شده اند، به دلیل اینکه از حد مشخصات بالایی (USL)، بالاتر هستند به عنوان محصول غیر استاندارد به شمار میآیند. شرکت ها با توجه به استراتژی های خود، ممکن است این محصولات را دور ریخته و یا مجددا وارد چرخه تولید کنند. البته برخی شرکت ها نیز با توجه به تمرکز زیادی که بر روی کیفیت کالا دارند، از روش های جدید تری استفاده میکنند تا میزان واریانس در تولید را به صفر نزدیک کرده و با این کار نه تنها هزینه حاصل از تولید قطعه معیوب را کاهش میدهند، بلکه از دید مخاطب نیز به عنوان تولید کننده یک محصول با کیفیت شناخته میشوند.
حال با الگوبرداری از مثال بالا، میتوان از این روش در فرآیند داده کاوی برای شناسایی داده های پرت که ویژگی های متمایزی نسبت به سایر داده ها دارند استفاده کرد. چرا که کلیه داده ها در حدود خاصی از نظر تنوع ویژگی ها نوسان کرده و در بین آن ها، داده هایی که دامنه نوسان بسیار بیشتری دارند، همانند محصولات معیوب و دور از استاندارد های تعیین شده، به عنوان داده های پرت شناسایی میشوند.